本文共 6384 字,大约阅读时间需要 21 分钟。
0. 概述
- 我们知道,Java 中的关于 ‘流’(Stream)的 API 分为两类,即 字节流 和 字符流,其中字符流是字节流解码后的形式,而字节流是字符流编码后的形式,字节流也是计算机内部的存储形式。所以一切从字节流开始。
- 这里说一下 BufferedInputStream,它的类继承层次如下:
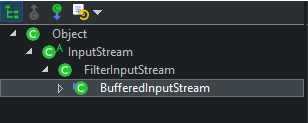 其中,过滤器流(FilterInputStream)是一个抽象类,它希望它的子类使用一个 InputStream 类型的对象实例初始化它,并且其子类可以通过覆盖父类方法为流提供额外的功能,这也是设计 FilterInputStream 这个抽象类的目的。
其中,过滤器流(FilterInputStream)是一个抽象类,它希望它的子类使用一个 InputStream 类型的对象实例初始化它,并且其子类可以通过覆盖父类方法为流提供额外的功能,这也是设计 FilterInputStream 这个抽象类的目的。 - 下面是一个简单的示例:
public class Temp { public static void main(String[] args) throws IOException { String fileName = "data.txt"; File file = new File(fileName); FileInputStream fileInputStream = new FileInputStream(file); // 缓冲输入流 BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream); // do something // ... // close stream bufferedInputStream.close(); }} 通过 FileInputStream 示例对象,来构造一个 BufferedInputStream 对象,从而为 fileInputStream 对象提供额外的缓冲功能。其中 fileInputStream 为原始的字节流,它原生实现了 InputStream 接口,而 bufferedInputStream 是基于 fileInputStream ,通过覆盖它的方法从而添加额外的功能,而底层的流操作还是委托给了 fileInputStream 。这里有个问题,即 这里的变量 fileInputStream 和 bufferedInputStream,其中 bufferedInputStream 内部保存了对 fileInputStream 的引用,它们本质都是操作同一个流对象,只是 bufferedInputStream 提供了额外的功能,如果在程序中混合使用这两个对象,则可能造成混乱(特别是分别通过这两个对象进行读取操作的情况)。
示例:import java.io.BufferedInputStream;import java.io.ByteArrayInputStream;import java.io.IOException;public class Temp { public static void main(String[] args) throws IOException { byte[] bytes = { 'A', 'B'}; ByteArrayInputStream is = new ByteArrayInputStream(bytes); BufferedInputStream bis = new BufferedInputStream(is); int a = is.read(); // 1. 通过 is 读取 int b = bis.read(); // 2. 通过 bis 读取 System.out.println("" + (char)a + (char)b); // 两次读取操作的集合组成完整的数据 }} 程序中,两次读取操作的集合才能组成完整的原始数据。
如果不需要使用底层的或中间的流对象提供的特定操作,则可以将多个流对象的创建嵌套在一起,使得最终只产生一个对末端流对象的引用,这样便可以避免混乱。修改代码如下:import java.io.BufferedInputStream;import java.io.ByteArrayInputStream;import java.io.IOException;public class Temp { public static void main(String[] args) throws IOException { byte[] bytes = { 'A', 'B'}; BufferedInputStream bis = new BufferedInputStream(new ByteArrayInputStream(bytes)); System.out.println("" + (char)bis.read() + (char)bis.read()); }} 本文开头的示例程序,也可以修改为:
import java.io.BufferedInputStream;import java.io.File;import java.io.FileInputStream;import java.io.IOException;public class Temp { public static void main(String[] args) throws IOException { String fileName = "data.txt"; // 缓冲输入流 BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(new File(fileName))); // do something // ... // close stream bufferedInputStream.close(); }} 1. BufferedInputStream 类的实现
- 来看看 BufferedInputStream 类的内部实现,我认为该类内部定义的几个变量对于理解该类的行为来说非常重要:
- 首先,pos 变量,该变量表示内部数组中下一次 read 操作时 ‘读取位置’ 的下标,即 下一次读取操作的起始位置,而其有效值为 ‘0 到 数组长度’ 即 区间 [0, 数组长度]。
- count 变量,该变量的取值为: ‘内部缓存区数组的最后一个有效字节的下标’ + 1,也就是说,count 是有效数组元素的边界,其自身便是下一次写操作的起始位置。当 pos = count 时,则表示 pos 指向了一个无效的读取位置,这时缓存区中没有数据可供读取,所以需要从底层流中读取数据了。
- 注意,该缓存区的实现中,不会出现 count > pos 的情况 即 count 在 pos 的左边(写操作在读操作的左边,即写操作快于读操作),这可能是因为其支持 mark 标记,这样对缓冲区的写操作始终在读操作的右边进行,使得实现更为简单。
- 下面是使用 BufferedInputStream 的一个示例:
import java.io.BufferedInputStream;import java.io.ByteArrayInputStream;import java.io.IOException;public class Temp { public static void main(String[] args) throws IOException { // 生产字节,用于读取 int bytes_num = 10; byte[] bytes = new byte[bytes_num]; for(int i = 0;i < bytes_num;i++) { bytes[i] = (byte)(i + 1); } // 指定缓冲区大小为 5 BufferedInputStream is = new BufferedInputStream(new ByteArrayInputStream(bytes), 5); // 在 pos 为 0 的位置 mark,且 marklimit = 5 = 缓冲区长度 is.mark(5); // 连续读取 5 次,最后 pos = count = 5 = 缓冲区长度 for(int i = 0;i < 5;i++) { is.read(); } // 当再次读取时,前面标记的 mark 位置,将被失效 is.read(); // 读取了数值 6 // 想要回到起始位置,再次进行读取时,reset 方法抛出异常 try { is.reset(); } catch (IOException e) { e.printStackTrace(); } System.out.println(is.read()); // 打印结果为:7。“回不去了” }} 运行结果(reset 方法抛出异常):
java.io.IOException: Resetting to invalid mark at java.io.BufferedInputStream.reset(BufferedInputStream.java:448) at com.willhonor.test.network.Temp.main(Temp.java:28)7 // 打印语句输出。“回不去了”
当然,上面的示例是我有意构造的,但是在实际使用中并不是不可能出现,示例中,在第一次读取之前先 mark 当前位置,并且 mark 长度 等于 内部缓存数组的长度(其实这个需求也很简单:在之后的任何时间点都可能需要回到起始位置再次进行读取,所以在读取之前先 mark 当前位置),随后连续读取一个字节,直到读取第 6 个字节后,想要再次回到起始位置,此时调用 reset 方法报告异常(注意,此时底层流中是有数据的,只是 BufferedInputStream 提供的缓存机制报告异常),BufferedInputStream 并没有着急扩大缓存区,而是将 mark 标记失效掉了,将 pos 和 count 重置为 0,导致丢弃当前所有已缓存数据(代码中给出的注释是“buffer got too big, so invalidate mark and drop buffer contents”)。
可以通过调整 mark 的参数,来避免上述的缓存数据丢失,而且直接导致 BufferedInputStream 扩大缓存区,示例代码如下(仅仅修改了 mark 函数的参数值):import java.io.BufferedInputStream;import java.io.ByteArrayInputStream;import java.io.IOException;public class Temp { public static void main(String[] args) throws IOException { // 生产字节,用于读取 int bytes_num = 10; byte[] bytes = new byte[bytes_num]; for(int i = 0;i < bytes_num;i++) { bytes[i] = (byte)(i + 1); } // 指定缓冲区大小为 5 int buf_size = 5; BufferedInputStream is = new BufferedInputStream(new ByteArrayInputStream(bytes), buf_size); // 在 pos 为 0 的位置 mark,且 marklimit = (1.5 * 缓冲区长度) is.mark(Math.round(buf_size * 1.5f)); // 连续读取 5 次 for(int i = 0;i < buf_size;i++) { is.read(); } // is.read(); // 回到起始位置再次读取 try { is.reset(); } catch (IOException e) { e.printStackTrace(); } System.out.println(is.read()); // 打印结果为:1。“回到过去,试着让故事继续...” }} 运行结果为:
1 // 打印语句输出。“回到过去,试着让故事继续...”
将 mark 的参数设置为 当前数组长度的 1.5 倍,也会导致随后缓存区数组长度扩大为原来的 1.5 倍(注意数组的最大扩大倍数为 2),且已标记的缓存数据并不会被丢失。当数组长度被扩大一次后,如果一直需要达到上述的 mark 效果,必须在执行读取操作之前再次调用 mark, 参数计算方式不变,但是其中数组的长度必须更新为当前扩大后的数组长度,可是 BufferedInputStream 并没有提供获取内部缓存区数组长度的方法,所以这一点必须自己来做,那就将数组的长度记录下来呗。
刚刚在看 Buffer 类,其中的思想与 BufferedInputStream 类一致!Buffer 类的 API 文档介绍如下:
- A buffer is a linear, finite sequence of elements of a specific primitive type. Aside from its content, the essential properties of a buffer are its capacity, limit, and position:
- A buffer’s capacity is the number of elements it contains. The capacity of a buffer is never negative and never changes.
- A buffer’s limit is the index of the first element that should not be read or written. A buffer’s limit is never negative and is never greater than its capacity.
- A buffer’s position is the index of the next element to be read or written. A buffer’s position is never negative and is never greater than its limit.
- 其中的 capacity 对应 BufferedInputStream 中的数组 buf 的 length
- limit 对应 BufferedInputStream 中的 count 变量
- position 对应 BufferedInputStream 中的 pos 变量
转载地址:http://kjlsi.baihongyu.com/